
��ȫרҵЭ��ISACA����ȫ���20������֤��ȫרҵ��Ա�Ƴ�AI��ȫ��������֤��AAISM�����о���ʾ61%�İ�ȫרҵ��Ա��������ʽAI����в��Ϊ�����á�����֤����AI��������Ŀ���������չ������������������������������ϸ

�ڹȸ��ư�ȫ����ϣ��ȸ��������AI��ȫԸ���ĸ���ϸ�ڡ��ù�˾�Ƴ����ܰ�ȫ��Ӫ���ģ�ͨ��AI�����Ż����ݹܵ����Զ�������������¼���Ӧ�����̹������̡��µľ��������������Mandiant����ʦ�Ĺ������飬����ϸ

Lumen Technologies������������������ĺ������ӽ����ش���������16�������ӳ��е�70������������������ṩ�ߴ�400Gbps��̫����IP���ù�������֧�ֿͻ����迪ͨ������������ɴ������ã���߿���չ��400Gb����ϸ

RtBrick�о����棬��Ӫ������AI����ý������������"ѹ����"���ա�������ʾ87%��Ӫ��Ԥ�ڿͻ���Ҫ����߿����ٶȣ���81%�������мܹ���Ӧ����һ��AI����ý��������84%��ӳ�ͻ������ѳ�Խ��������������91%Ը��Ͷ�ʡ���ϸ

Pine64����ͣ�������ߵĸ߶������ֻ�PinePhone Pro��ת��רעRISC-V�ܹ���Ʒ�������ò�Ʒ�������δ��������2025���Ե����ù��͡�����������ǣ��Ͷ�PinePhone�������������ꡣ��˾ͬʱ�Ƴ����RISC-V�������������ϸ

�������������VSP One SDS��������洢��������Azure�г����ߣ���AWS�ȸ���֮���һ����չ��ԭ����洢���ý������֧�ֿ�Azure�ͱ���ϵͳ�����ݹ����뱣�����߱��������á�ѹ����˫���첽���ƹ��ܣ�ͨ��VS����ϸ
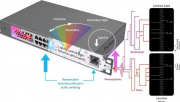
��ѧ���齻�������ٵĸ��������ǹ��ź����洢��ʹ�ö�ȡ�����ݰ�ͷ��Ϣ���������ܡ�������˾Finchettoͨ�����·����������һ���⣺�ڴ������ݰ���ͬʱ���ò�ͬ�����Ĺ��ź�Я��Ŀ�ĵ���Ϣ��ʵ�ֹ���ƹ�Ľ������ơ���ϸ

Python�������������JetBrains�����ڰ˴�Python�����ߵ��飬��3���˲��롣������ʾPythonʹ���ʳ���������50%�ܷ��߱�̾��鲻�����꣬39%�ڽ����꿪ʼʹ��Python��Web����ռ46%�����ݷ���ռ48%��FastAPI���ʹ���ʡ���ϸ

����ӵ�ж��վ�����֯��VMware�ɱ�������в��Զ�̰칫�ҵĶ�����Ӫ���������������������ƶ����ܵ������ɷ��ã��������˶Գ������ӵ������ͷ��ա���֯Ӧ��˻���������������������ʩ��Ѱ���ܹ��������⻯���洢������ϸ

������AI����ƽ̨��Elasticsearch���ɣ�ͬʱPowerEdge R7725�������䱸Ӣΰ��RTX Pro 6000 Blackwell GPU����ƽ̨�����ǽṹ���������棬�߱�������������������ͻ�Ϲؼ����������ܣ���Ϊ�������������������ṩʵ����ϸ

Confluent��˾����Confluent Cloud for Apache Flinkƽ̨���Ƴ���ʽ�����¹��ܣ�ּ�ڰ������ڡ�ҽ�ơ�������ҵ��������ʵʱ���ݵ�������AIӦ�á��ù��ܽ�ʵʱ�������봦���ܵ���ʹAI�������ܹ�����ҵ��仯������������ϸ

���ֻ�ת����Ŀ�����Ը�������ʼ������ʵȴ������CIO���ܴ����ԭ������ʵ�ֲ�Ʒ�����̡���Ӫ�ͼ���ջ�ִ����ļƻ�ͻȻƫ�����������ܽ��������ؼ�����ȱ��ʵ����ҵ��ֵ��Ŀ���λ��ҵ���쵼��Į�����ġ��쵼��������ϸ
Ӣ�ض��������ڳ���57�����Ĺؼ�ʱ�ڡ�����IJƱ��������������г��ĸ߶ȹ�ע�㷺���ۣ���2025��Q2�Ʊ�������Ӣ�ض��Ƚ��Ƴ̳�Ϊ���㡣����ϸ
��ȫ��ҵ�������ƶ��£���ͳ����ҵ�����������ܻ������ֻ�ת�ͣ���ؼ����ڽ���������רҵ֪ʶ�����������ѧϰ��ϣ����������û��ĸ�Ч����ϵͳ������ϸ

OpenAI��ϯִ�й�Sam Altman��ʾ������Ͷ���ߵ�AI�����ʹ����ʱ�֧��������Ŀǰ������AI��ĭ�С�������Ͷ���߶�AI�����˷ܣ�������ΪAI�dz�����������Ҫ�ļ�����ChatGPTĿǰӵ��7���ܻ�Ծ�û�����ȫ��������վ���ɡ���ϸ

Ӣΰ���Ƴ��µ�С������ģ��Nemotron-Nano-9B-v2��ӵ��90�ڲ�������ͬ��������б�����ѡ���ģ�Ͳ���Mamba-Transformer��ϼܹ���֧�ֶ����Դ����ʹ������ɣ����ڵ���A10 GPU�����С����صĿ��л��������������û�����ϸ

��Android Police�������ȸ跭�뼴��ӭ���ش�AI���������°汾9.15.114��ʾ����ģ��ѡ����������"����"��"��"����ģʽ������ģʽ�����ڲ˵�����ȼ�����ģʽ��ʹ��Gemini�����ṩ��ȷ�����������⡣���¡���ϸ

����AI������ʽAI�Ŀ����ռ�����֯�����ݴ�����Ӧ�üܹ�������������ս����ͳ����ʽ�ܹ����������ִ�AIӦ�õ����������ƶ�AI�������������ɺ;����ƶ��ı�Եλ��ת�ơ���ԵAI�������ٴ������ơ�GPU��Դ�������Ӫ������ϸ

��ҵ�ձ���ΪAIģ����Ҫ������������Hugging Faceר����ΪӦ�ø����ܵ�ʹ��AI������ؼ���������Ϊ�ض�����ѡ����ʹ�ģ��ģ�Ͷ���ͨ�ô�ģ�ͣ���Ч����ΪĬ��ѡ����ⲻ��Ҫ�ĸ߳ɱ�����ģʽ��ͨ���������;��ȡ���ϸ
������dz����е����˽�IT�������²�Ʒ�뼼����Ϣ����ô���������������ʼ������������;��֮һ��



