7��23�գ�2025����ԭ�ӿ�Դ��̬��ῪԴ���������ݽ��ڱ������һ������ijɹ��ٰ졣���۽���Դ���ɼ������¡��˲ŷ�չ���ҵ��أ�ȫ����֡�Powered by OpenHarmony����̬�Ľ��Խ�չ�����ʵ��������ϸ
2025��7��23�գ���BOE�������������Ͼ�����OPPO��OUTPUT����Ĺ�����Ӱ����һ���� ����ǰ������ů���ߣ��ⲻ����һ������������ӽ��ǿյĵط����Ƽ���γ�Ϊһ����ů���ᶨ�Ĺ⣬������������Ĺ��£�����BOE��������ϸ
7��22�գ������찲����������̬Ȧ��ᣨAAES2025���ں�����ʽ�����Ļ�����η���ԡ�����δ����AIʱ����������̬��Ϊ���⣬��۹�����֪��������̬��������飬Χ�ơ����ܼ�ʻ����������Դ��������������AI��硭��ϸ
AI���ŶȵĹؼ�������֮һ��ģ��Ӧ�����ȡ���һ��������ҵ��������֤����ϵͳ��ʹ�õ�AI�������Դ����ȫ�Ժ�һ���ԵĿ�ܡ�����������˽�AIģ������ι�����ѵ���Ͳ���ģ��ͼ��������ܶ�ϵͳ������з��շ֡���ϸ
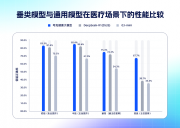
��˽�����ģ��ͨ��12������ҽʦ���ԣ�������ҽѧ����ʹ�á�����ϸ

�������ұ������ܵĽ�������ƣ�������������ȫϵͳ����ͥ��¥���Զ����İ�װ����ϸ

���º���ͺ�Ϊ��Ƶ����ҵ��ҽ������ṩ�������л����ܡ���ϸ

Colt�Ƽ�����˾�Ƴ������ӳ������ӷ���Colt ULL DCA��ר��������ܻ��ҽ����̺�AIӦ�ÿ�����ҵ�ĸ������÷����ϳ����ӳ������ר���ƽ���ƽ̨���ƹ������������ṩר�ø���·������AWS������������У�ƽ���ӡ���ϸ
�������ڣ�������һ�ġ�ϵ�л������ȫ��λΪ�û��������������û������ڻ�Ϊ������ҵ���������ö��Ķ�Ŀ�ĵأ��û�Ϊ���ͨ9.9Ԫȫ�����������ý���������գ��û����ͼ������ɫ��������������С�շ������á���ϸ
�� PTC������ʼ�����ţ���߿ɳ����Ե���ҵʵ���ǽ��������������ɹ����ϵ�ʵ����Ψ����ˣ�����ʵ�ֳ��ڵIJ��ú���Զ��Ӱ�졣����ϸ
2025��7��23�գ�����������2025����ԭ�ӿ�Դ��̬��ῪĻʽ�ϣ���Ϊ�ն�BG CEO�θշ�����Ϊ���������������Դ��ʹ��ǧ����ҵ���¡��������ݽ��������˻�Ϊ�ڿ�Դս���ϵij���Ͷ����ʵ���������˿�Դ������̬��չ�ɹ�����ϸ

Լ�����ս�˹��ѧ�о��Ŷӿ�����ETTINģ�������״�ʵ���˱������ͽ�����ģ�͵Ĺ�ƽ�Ƚϡ��о����ֱ������ó��������������ó����������ѵ��Ч�����ޡ����о�ΪAIģ��ѡ���ṩ�˿�ѧ���ݣ����������ѿ�Դ������ϸ

�������Ǵ�ѧ�Ŷӿ����������ǿ��AIϵͳ��ͨ�������з������ı����༼�����������������������������Ա����ʶ��ȷ�ʡ����о������������ԣ��ڶ������������ȡ������ɼ���Ϊ��������Ϣ������ý�������ṩ�ˡ���ϸ

�������㽭��ѧ����Ρ�����Ŷ�����ţ���ѧ�����ϼ��ŵȻ���������SpatialTrackerV2ϵͳ��ʵ���˽�����ͨ����ͷ���ܾ�ȷ����Ƶ����������ά�˶��켣��ͨ�����µ�ͳһ��ܺʹ��ģ����ѵ�����ü�����Ȩ�����������ϸ

�����Ŷ����RLEP������ͨ�������ط���AI���ɽ��һ���ظ��ɹ�·��������ѧ����������ʵ��ѵ��Ч�ʺ�����˫���������÷�����Ϊ�����ռ����ط�ѵ�����Σ���AIME��AMC������ȷ������1.7-5.2���ٷֵ㣬ѵ���ٶ���������ϸ

Qualcomm AI Research�Ŷ������һ�ִ��·�����ͨ����С����ģ��ʹ�ñ�̹��߶��dz���˼����������������⡣�о����֣�1B��3B������Сģ����ʹ������"�༭��"����ʱ���ɹ��ʷֱ�������6����2����Զ����ͳ˼ά��������ϸ

����������ѧ�о��Ŷӿ�����PhysXGenϵͳ���״�ʵ�ִӵ���ͼƬ���ɾ��������������Ե�3Dģ�͡��ü��������˰���2.6�������������������ݿ⣬��ȷԤ������ijߴ硢���ʡ����ܺ��˶����ԡ�ϵͳ�ڸ���ָ����������Խ����ϸ
��ȫ��Ƽ������Ӿ�ı����£��й������ԡ��ؼ�������������Ϊ����ս�ԣ������ƽ��˹����ܡ���ģ�͡�AIоƬ����������ϵͳ��5G����������ȼ�����ϵ���衣����ϸ

Ƥ���о��������·�����ʾ���ȸ��������ҳ���AI�������������������û���������վ�ĵ���ʡ��о����֣�û��AI�ش�����������Ϊ15%������AI��������������ʽ���8%��ĿǰԼ���֮һ����������ʾAI��������������������ϸ

GlobalData�о���ʾ���˹�����������Ԥ����ά������Ϊ������ҵ��߿ɿ��Ժͳɱ�Ч��Ĺؼ���ɲ��֡��ü���������ݷ���������ѧϰ��ʵʱ��أ��ܹ���ȷԤ���豸δ��״������������ά���ɱ�30%������豸������2����ϸ
������dz����е����˽�IT�������²�Ʒ�뼼����Ϣ����ô���������������ʼ������������;��֮һ��



