
Adobe Research团队联合香港中文大学开发了EditVerse,这是首个统一处理图片和视频编辑的AI模型。它采用创新的交错序列设计和四维位置编码,将文本、图片、视频转换为统一表示,实现跨模态知识共享。研究团队创建了2…详细

沃尔玛宣布与OpenAI达成合作,消费者将能够通过ChatGPT聊天机器人购买沃尔玛产品,包括日用品、家庭必需品等,并可即时结账。该智能购物功能还支持山姆会员店用户进行餐食规划和补货。用户需将沃尔玛账户与ChatGPT关…详细
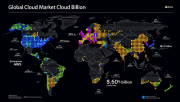
企业云基础设施服务支出在2025年第二季度达到990亿美元,同比增长25%。生成式AI系统成为关键驱动力,IaaS和PaaS服务增长27%。亚马逊AWS占据30%市场份额领先,微软Azure和谷歌云分列二三位。专业化新云服务提供商表现…详细

NetApp发布全闪存AFX阵列,采用分解式架构独立扩展存储与计算资源。新增AI数据引擎可为大语言模型预处理ONTAP数据,提供勒索软件防护服务并增强谷歌云集成。AFX系统支持高达128个存储控制器集群,容量超过1EB,内置A…详细
AWS等主要云服务提供商希望将大型机应用迁移至公有云,但许多应用仍停留在原有环境中。VirtualZ提供桥接解决方案,使大型机数据能够被公有云应用访问。AWS Transform for Mainframe服务可帮助组织迁移老旧大型机应用…详细

Arm与开放计算项目合作,推出AI数据中心高效基础设施标准以应对能耗挑战。传统数据中心依赖分离式服务器板连接各组件,而SoC设计将计算、内存和网络接口集成到单一芯片中,降低功耗和延迟。Arm贡献基础芯粒系统架构规…详细

三星和SK海力士将与OpenAI合作在韩国建设星门数据中心,这是OpenAI全球基础设施推进计划的一部分。星门项目总投资5000亿美元,计划到2029年建设20个AI数据中心。两家韩国内存制造商将把芯片产能扩大至每月90万片晶圆…详细

东芝验证了12碟片硬盘驱动器技术,相比其10碟片微波辅助磁记录技术容量提升20%。该公司目前的10碟片硬盘最高容量为28TB。新的12碟片技术需要更薄的碟片和4个额外的读写磁头,东芝是业界首家实现此技术的制造商。通过…详细

航空运输行业技术提供商Sita发布高速光纤服务,提供超可靠、可扩展且安全的连接,有望在复杂机场环境中取代铜缆。Sita无源光网络技术可覆盖20公里距离,无需中间设备,有效支持高清视频监控、智能终端、物联网设备和…详细

芬兰国家技术研究中心VTT与IQM量子计算机公司合作,推出欧洲首台50量子比特量子计算机。IQM通过公开招标获得了向VTT交付300量子比特超导量子计算机的合同,该项目由芬兰政府7000万欧元资助,计划2027年第四季度交付。…详细

宾夕法尼亚大学研究团队开发了PhysCtrl系统,能从单张照片生成符合真实物理定律的视频。该系统通过学习55万个物理仿真数据,结合空间-时间注意力机制和物理约束,准确预测不同材质物体在外力作用下的运动轨迹,解决了…详细

Google DeepMind最新研究发现,视频生成AI模型Veo 3展现出惊人的零样本学习能力,能够在未经专门训练的情况下完成图像分割、边缘检测、迷宫求解等多种视觉任务。研究团队通过18,384个视频样本验证了这一发现,认为视…详细

北航团队开发的GeoSVR技术突破了传统3D重建方法的局限,采用稀疏体素表示和体素不确定性评估,无需依赖初始点云即可实现高精度表面重建。该方法通过智能的深度约束和体素协同优化策略,在DTU等标准数据集上取得了最佳…详细
主题会议上,浩辰软件发布和展示了最新的浩辰CAD 2026、浩辰AEC设计软件集2025、浩辰BIM 2025,以及重磅新品浩辰-ZIXEL 3D CAD等全系列产品线与浩辰CAD AI技术革新,系统呈现了浩辰在产品体系、未来战略等方面的关键…详细

Google DeepMind团队发布了EmbeddingGemma,这是一个仅有3.08亿参数的轻量级文本理解模型,却能达到7亿参数模型的性能水平。该模型在权威的多语言文本嵌入基准测试中排名第一,支持250多种语言,特别适合移动设备部署…详细

日本奈良先端科学技术大学等机构首次深入研究AI编程工具Claude Code在真实开源项目中的表现。通过分析567个代码贡献,发现83.8%被成功接受,54.9%无需修改直接使用。AI擅长重构、测试和文档工作,但需要人工修正bug处…详细

这项研究首次创建了CommonForms大规模表单数据集,从800万PDF文档中筛选出5.9万份高质量表单,涵盖20多种语言和14个领域。基于此训练的FFDNet模型在表单字段识别上超越Adobe Acrobat,能识别文本框、复选框和签名区域…详细

Meta公司联合多所大学发布"软令牌"新技术,首次实现AI连续推理训练。该方法让AI摆脱传统的逐步推理模式,能同时探索多种思维路径,如人脑般灵活思考。在数学推理任务中,新技术保持了原有准确率,在多样性指标上显著…详细

华盛顿大学研究团队开发的PEEK系统通过视觉语言模型为机器人提供路径和重点区域指导,实现了机器人操作任务的零样本泛化。该系统将复杂的环境理解交给专门的视觉模型处理,让机器人专注于动作执行,在真实环境测试中…详细
如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。




